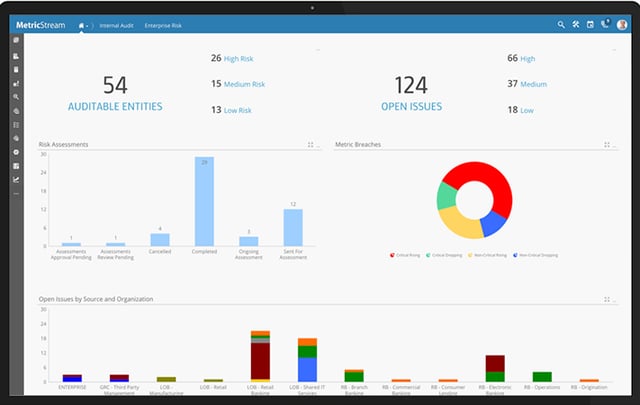
Building a hybrid cloud environment is a hassle, but the light at the end of the tunnel has always been that eventually the enterprise would have a fully abstract, infinitely scalable, self-managing data environment that can cope with the frantic workloads of the digital economy.
But while the vendor and provider communities have been quick to implement the abstraction and the scalability on hybrid platforms, the self-managing aspect has been a little slower to evolve. This is understandable given that true application and data portability has only recently emerged under still-nascent container architectures, but in retrospect it also appears that full-stack, end-to-end automation of the hybrid cloud is not exactly a walk in the park.
Even now, as self-managing platforms finally enter the channel, there is still some question as to how well they will function in real-world production environments. Cisco’s Project Starship, for one, is still more of a vision than an actual product, although tech analyst Matt Kimball says that what the company has shown so far is impressive. The system utilizes highly granular telemetry data collected from thousands of servers and uses machine learning and artificial intelligence to provide real-time analysis to deliver “intent-based computing.” This is what enables users to define what they hope to accomplish and then let the systems handle all of the messy details around provisioning, integration and optimization. So far, however, only the first piece of this architecture – the Intersight multi-cloud management system – has been released.
Meanwhile, multiple platform providers are rolling out self-managing or self-governing solutions that promise to lower costs and improve performance across private and hybrid infrastructure. Turbonomic recently introduced version 6.0 of its software that focuses on database and storage optimization for workloads tied to Azure and AWS cloud deployments. The system features automated storage tier adjustment and database control to manage resource consumption in dynamic data environments, as well as pre-paid capacity control and idle resource reclamation to control costs and streamline infrastructure footprints. The company says all of these functions are handled in real time with no human intervention, allowing IT staff to concentrate on higher-level architectural and strategic initiatives.
Another promising solution is ZeroStack’s Z-COS platform that the company bills as a “self-driving private cloud.” According to tech consultant Dan Kusnetzky, ZeroStack is a step ahead of other systems in its class because it integrates complex monitoring and management with the machine learning and predictive analysis tools found on the company’s Z-Brain cloud portal. This provides a high degree of self-management and self-healing of on-premises clouds that makes it easier to integrate legacy x86 workloads. As well, the system supports key Big Data and devops tools like Hadoop, Spark and the Jenkins CI/CD suite, plus application servers like Apache and NGINX.
New service-layer solutions are also working toward self-management status. The Qubole Data Service (QDS) now provides native support for Microsoft Azure and the Azure Data Lake Store to enable tools like workload-aware auto-scaling and minute-based billing that the company says can reduce TCO by up to two-thirds. The system also leverages AI and ML to simplify the deployment and management of Big Data workloads, particularly those that tend to burst data into the cloud at random times. With Qubole, Azure users gain a turnkey analytics layer that can be put into action quickly and then left to manage workloads on its own as both infrastructure and application needs require.
Does any of this amount to a fully automated data ecosystem? Probably not, although that is an awfully high bar to reach, even for small and mid-sized enterprises that do not have a lot of legacy silo infrastructure to deal with. But as the cloud becomes more automated, enterprises should not expect to one day find themselves with a “set it and forget it” infrastructure stack. The most intelligent automation system is only as good as the data it can access and the outcomes it’s been told to achieve. And as we’ve already seen with today’s conventional automation, every time an IT tech takes his hands off one process, he has to put them on another.
Arthur Cole writes about infrastructure for IT Business Edge. Cole has been covering the high-tech media and computing industries for more than 20 years, having served as editor of TV Technology, Video Technology News, Internet News and Multimedia Weekly. His contributions have appeared in Communications Today and Enterprise Networking Planet and as web content for numerous high-tech clients like TwinStrata and Carpathia. Follow Art on Twitter @acole602.