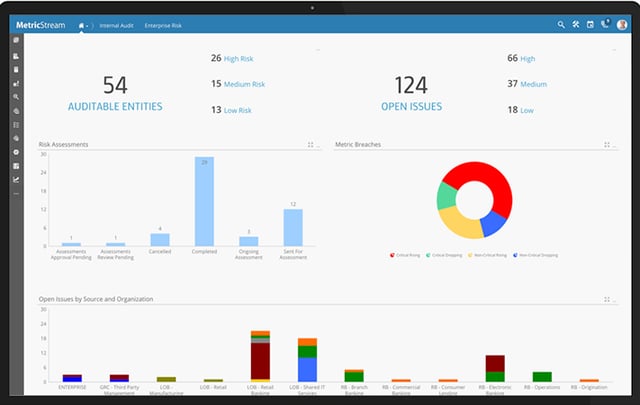
Data Lakes: 8 Enterprise Data Management Requirements

The enterprise is under the gun to convert existing infrastructure to more nimble, automated footprints that better support Big Data and the Internet of Things (IoT). This invariably leads to the creation of the so-called “data lake” that acts as both a warehouse and an advanced analytics engine to turn raw data into valuable, actionable knowledge.
The problem is, development of key technologies that go into the data lake is still at a very early stage, so organizations that want to be on the cutting edge of this trend have little or no guidance when working through the inevitable complications that arise in such an ambitious project.
According to Constellation Research principal analyst Doug Henschen, technical challenges will remain for some time, but there are ways to ensure that your data lake does not turn into a data swamp. One of the key pitfalls is thinking that the data lake is a single, monolithic entity rather than a collection of integrated components. The best designs focus on blending raw data sets to find correlations, model behaviors and present predictable outcomes, but this requires careful coordination between data ingestion, refinement, experimentation, governance and other functions. To date, platforms like Apache Hadoop incorporate all of these processes, but it will be a while before a truly integrated architecture hits the enterprise mainstream.
Building the lake is only the first challenge, however. As Podium Data’s Bob Vecchione notes, the next step is keeping data flows intact as workloads mount. A little-known aspect of Hadoop is that files are never updated, just recreated as new files. If not managed properly, the data lake can quickly scale to gargantuan levels full of undecipherable, untraceable data. This is why lakes need sophisticated metadata engines and hierarchical directory structures to maintain transparent records of file and data creation, as well as default partitioning and data removal to prevent key sets from becoming so large they impede performance.
Before you even begin, however, it is important to establish clearly defined use cases for your data lake, says Loraine Lawson for Enterprise Apps Today. Most organizations view the lake as a means to pull data from all enterprise applications into a single Hadoop repository, but experts like Pentaho CTO James Dixon say this strays from the original concept, which was to provide data ingestion and blending only when necessary. Rather than a catch-all for every piece of knowledge the enterprise obtains so that it will magically solve all your problems, the lake should focus on targeted results using only relevant data. The overarching goal should be to optimize data, not preserve it in its raw form.
Another problem is that too many people cannot distinguish between the data lake and the data warehouse, says Cambridge Semantics CTO Sean Martin. Going forward, a key differentiator will be the introduction of semantic graph query engines and other tools in the data lake to enable contextualization, discovery, visualization and other capabilities across the repository. This will help overcome the lack of skills among knowledge workers when running the advanced analyses and data conditioning necessary for high-speed results, and it also lessens the cost and complexity of the lake compared to traditional warehouses built around standard Oracle, IBM and Microsoft platforms. In the future, then, it isn’t enough to just build a data lake – it must be built around new generations of smart technology.
Any way you look at it, building and managing a data lake is not for the faint of heart. There is very little actual experience with the key technologies in play here, and virtually none when operating at scale, so any project at this point will require a lot of creative problem-solving and an architecture that can be reconfigured with relative ease.
And when all is said and done, it won’t be the lake itself that delivers the crucial insight that fulfills the ROI, but the people who use it.
Arthur Cole writes about infrastructure for IT Business Edge. Cole has been covering the high-tech media and computing industries for more than 20 years, having served as editor of TV Technology, Video Technology News, Internet News and Multimedia Weekly. His contributions have appeared in Communications Today and Enterprise Networking Planet and as web content for numerous high-tech clients like TwinStrata and Carpathia. Follow Art on Twitter @acole602.
Save