We have reached an inflection point in the rate of data creation that, unless you are willing to start throwing huge quantities of it away, you simply cannot afford to continue using the same technologies and tools to store and analyze it. The existing data silos – impractical for many reasons beyond pure expense – simply must be consolidated, even if the full picture of exactly how the utility of each piece of data will be maximized is still unknown.
One potential option many businesses have chosen to pursue in the hopes of addressing current business concerns while also maximizing future possibilities and minimizing future risks is building a data lake. With that, however, comes a separate set of challenges and considerations.
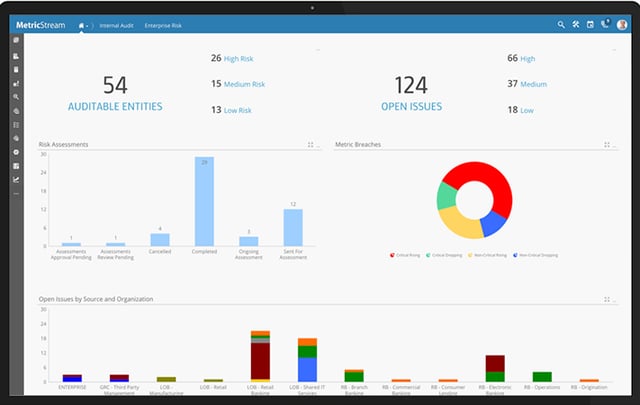
Large data volumes drive the need for data lakes. In simple terms, a data lake is a repository for large quantities and varieties of data, both structured and unstructured. The data is placed in a store, where it can be saved for analysis throughout the organization. In this slideshow, Storiant, a cloud storage provider, has identified six tips on how a data lake can reconcile large volumes of data with the need to access it.

Six Tips for Working with Data Lakes
Click through for six tips on how a data lake can reconcile large volumes of data with the need to access it, as identified by Storiant.

Realize the Importance of Reliability
For organizations whose data scale extends into petabytes, reliability is crucial. Most systems seem reliable on the surface, but data loss is common when the volume approaches this higher scale. Erasure coding is often used in such instances, but the reliability comes at the expense of high streaming performance. (It also requires significant compute and networking resources.)

The larger the data set gets, the more important it is that the metadata – in effect the index to the data stored in the data lake – not only be flexible and extensible, but scalable in its own right. The ability to make sense of the varied and vast set of objects in your data lake is going to depend on the capabilities of the metadata system. Without the appropriate metadata and the underlying mechanism to maintain it, you risk creating what Gartner calls a “data swamp.”

Ensure Compatibility
Today’s high-capacity storage systems have numerous advantages (among them flexibility and scalability), but often were designed with HTTP API’s that may not be fully compatible with all applications for moving data in and out. It is important that the data lake technology has a good compatibility story, and a cost-effective means of integrating with standard protocols and applications such as NFS, CIFS, S3, etc.

Make Compliance a Priority
One of the chief business drivers behind consolidating data silos is the increasing need to comply with regulatory or other legal requirements. SEC rule 17a-4(f), Dodd-Frank and simple patent defense are examples where data owners must be able to first certify that their data has not been modified, deleted or tampered with. Also, businesses should be able to produce the data in a reasonable amount of time, generally 24 hours. This can be a huge challenge when the data is in separate silos or in systems that don’t natively support compliance properties and high streaming throughput.

Consider Ingest and Download Speeds
The ability to stream data in and out of the system is critical no matter what kind of analysis you may ultimately want to perform. Today, people experimenting with Hadoop generally create a separate, not terribly reliable HDFS-based repository for data under analysis. Over time, this model is not feasible. The data lakes of the future must be able to present themselves as potential sources for MapReduce type analysis. Additionally, they need to deliver the data at very high rates of speed over parallel streams to the compute engine(s).

Utilize the Flexibility
Most of the technologies under serious consideration for data lakes are object stores, and one of the primary hallmarks of an object store is its flexibility. Object stores are in some sense raw byte stores with metadata to describe what the contents of the object are, and so are released from the burden of having to treat a range of file types differently.