

The Hadoop Challenge for Business Intelligence and Analytics Users
![]()
Splunk extended the number of data sources to which its analytics engine can be applied by adding support for a broader range of NoSQL databases and mainframe data. The company also improved the overall usability of the Splunk application environment.
Version 6.1 of Hunk: Splunk Analytics for Hadoop and NoSQL Data Stores adds support for NoSQL databases such as Apache Accumulo, Apache Cassandra, MongoDB and Neo4j. According to Sanjay Mehta, vice president of product marketing for Splunk, as the number of databases being used across the enterprise continues to increase, IT organizations want to be able to apply Splunk analytics to more than Hadoop and traditional SQL databases.
Meanwhile, Mehta says Splunk is also moving to increase its appeal outside of its traditional IT organization base by enhancing the interactive analytics capabilities of the Splunk platform. Version 6.1 of Splunk Enterprise makes it simpler to drill down into a particular search request in a way that makes it easier to maintain context, says Mehta. That capability is critically important to business analysts that would like to use Splunk to explore a particular set of Big Data.
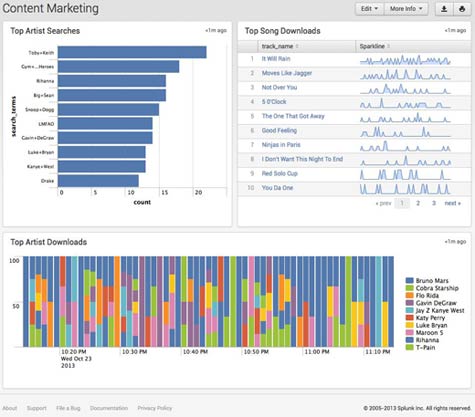
With the release of version 6.1 of Splunk Enterprise, organizations will also be able to use Splunk to explore data on a mainframe running Linux. With over 70 percent of the data in the enterprise still residing on a mainframe, Splunk Enterprise 6.1 now provides a much lower cost alternative for analyzing that data at a time when Linux is the fastest growing operating system on the mainframe.
Finally, version 6.1 also adds support for clustering to provide high availability and enhanced integration capabilities for embedding Splunk reports within other applications.
Primarily used for analyzing machine data in the era of Big Data, Splunk is being used across a broader number of applications. Much of that data is now stored in everything from logs to the latest NoSQL database platform. As the number of sources in which that data resides continues to multiply, it becomes more important to have an analytics platform that can correlate all that data regardless of where it actually resides.