
While Hadoop provides an excellent framework for storing massive amounts of data, deriving any business value from all that information is quite another matter altogether.
At the Hadoop Summit North America 2013 conference today, Splunk unveiled a beta version of Hunk: Splunk Analytics for Hadoop, an implementation of the analytics framework for Big Data that Splunk originally developed for a platform that is widely used to analyze the massive amounts of machine data generated by IT equipment.
According to Sanjay Mehta, vice president of product marketing for Splunk, the Splunk virtual index technology, including the Splunk Search Processing Language (SPL), is now being applied directly against Hadoop to give IT organizations a framework through which massive amounts of data can be analyzed.
Mehta says Hunk: Splunk Analytics for Hadoop is designed to allow users to detect patterns and find anomalies across petabytes of data. Rather than having to build schemas, Hunk: Splunk Analytics for Hadoop takes advantage of Hadoop to allow IT organizations to discover relationships between large sets of data that previously would not have been apparent.
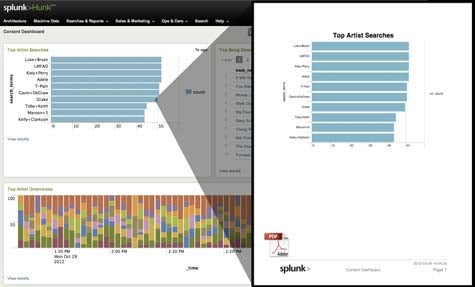
Hunk: Splunk Analytics for Hadoop also allows users to combine multiple charts, views and reports into role-specific dashboards that can be accessed via mobile computing devices.
As part of an effort to dramatically reduce the dependencies on expensive data scientists that are hard to find, Splunk Analytics for Hadoop is one of an emerging class of analytics applications designed to make Big Data much more accessible to the average business user. The benefit of this approach from an IT perspective is that it relies on a set of constructs with which many IT organizations are already familiar, given how much Splunk is already relied on to sort through logs generated by massive amounts of IT machine data.