

Flawed Integration Can Destroy Data Quality and Reliability
![]()
In a development that could have major implications for how document databases are deployed across the enterprise, MapR Technologies announced at the Strata + Hadoop World 2015 conference that its distribution of Hadoop can now natively support JavaScript Object Notation (JSON) using MapR-DB, the SQL engine that MapR runs on top of Hadoop.
Jack Norris, chief marketing officer for MapR Technologies, says that document databases based on JSON are much like any other engine that can be layered on top of Hadoop. The benefit of that approach is that it allows IT organizations to consolidate the number of individual classes of databases they need to support, says Norris.
In addition, Norris notes that it’s now simpler to combine analytics based on both SQL and JSON with a distribution of Hadoop that is optimized for real-time analytics applications. Via the Open JSON Application Interface that MapR Technologies is making available, developers of apps based on JSON can now also integrate those applications with Apache Spark in-memory computing platforms along with other databases and messaging systems, added Norris.
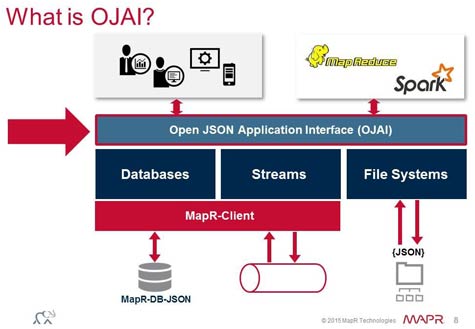
On the one hand, the last two years have brought about an unprecedented expansion in the types of databases that are being deployed across the enterprise. At the same time, Hadoop is clearly emerging as a cost-effective platform for storing massive amounts of data. Instead of copying that data into multiple databases, MapR is making a case for layering different types of data engines natively on top of Hadoop.
That approach should not only reduce the operational overhead associated with managing all those different types of databases, but it just might foster the development of composite applications that invoke SQL, JSON, Hadoop and Apache Spark when needed.