

Big Data: Eight Facts and Eight Fictions
![]()
Big Data analysis is fairly useless unless all the insight that can be garnered from making such an investment can be easily consumed across the enterprise.
With that goal in mind, at the Splunk Worldwide 2013 Users Conference, Splunk released version 6.0 of Splunk Enterprise, an upgrade to its analytics engine for machine data that is designed to be more accessible to a much broader base of end users.
As part of that effort, Splunk also unfurled Splunk Cloud, an instance of its software that is deployed by Splunk on top of the Amazon Web Services cloud, which can also be tightly integrated with on-premise instances of Splunk. In addition, the company has expanded the storage capacity of Splunk Storm, a free cloud service for developers that provides up to 20GB per month.
According to Sanjay Mehta, vice president of product marketing for Splunk, the Splunk user interface has been dramatically redesigned to allow non-technical users to make data-driven decisions based on the data discovered in Splunk or even another Big Data repository such as Hadoop.
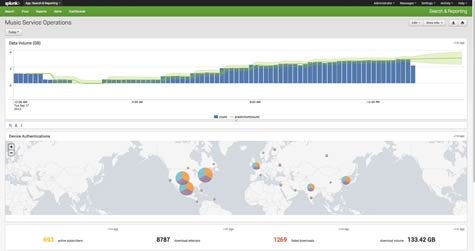
That ability leverages a new analytics store, pivot functions, and support for data models that have all been added to this release of Splunk Enterprise.
Without having to master any particular programming language, Splunk Enterprise 6.0 allows users to define relationships between data sets that can be more easily visualized and manipulated. And because Splunk relies on a late-binding data model, Mehta says users can iteratively launch queries in real time based on the previous answer to a question against Splunk data, while sharing the data model they created with other end users.
In addition, Mehta says Splunk has gone to considerable effort to make Splunk Enterprise 6.0 more accessible to developers who need to embed analytics of machine data within another application.
Mehta says it’s one thing to be able to gather data to create a Big Data repository; actually turning all that information into actionable intelligence requires tools that everyone from data scientists to the average business user can easily comprehend and invoke is a different task altogether. After doing so, says Mehta, the average organization can derive the real business value from its investment in Big Data.