
Most organizations today are not going to get a Good Housekeeping seal of approval for the way they manage data. And yet, now that data is the new oil, it’s critical that there be some architecture in place to store and manage data in a way that enables it to be consumed by machine learning algorithms that are driving the next wave of advanced artificial intelligence (AI) applications.
To bring some order to the data management chaos, IBM this week announced that it is adding a data catalog and additional data refining capabilities to the IBM Watson Data Platform. Rob Thomas, general manager for IBM Analytics, says for the first time, IT organizations can now make use of the IBM public cloud to manage data wherever it resides. The basic idea is to enable organizations to allow end users to self-service their own data needs using a catalog that in terms of design is similar to how end users navigate a music service such as Spotify, says Thomas. The existence of that catalog, adds Thomas, also serves to impose an information architecture (IA) on how data is then managed.
“I keep saying that you can’t have AI without IA,” says Thomas.
IBM this week demonstrated how the Data Catalog it has developed can pull metadata from across the enterprise to enforce compliance policies, and how an Analytics Engine that is now generally available makes it possible to separate how data gets analyzed from where it is physically stored.
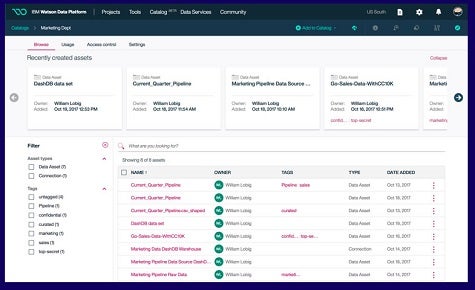
Rather than trying to build their own data catalog, IBM is essentially making the case for using a catalog that it built specifically to address data management and governance. In many ways, the IBM data catalog capability is similar to hiring a housekeeping service to help clean up a mess after a hoarder has been randomly storing various things for years. The only difference is that the IBM Watson Data Platform not only helps clean up the mess, it also helps prevent that mess from ever coming back.