
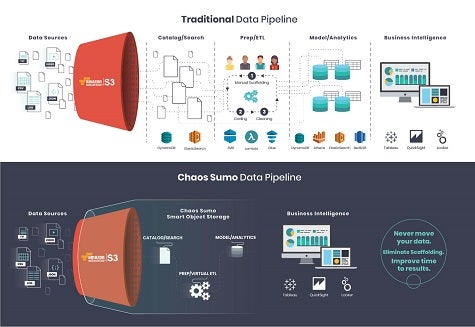
Gaining access to cloud storage is one thing, but being able to effectively provision and manage it often winds up being another thing altogether. To address that issue, Chaos Sumo developed a data discovery, management and analytics service that resides directly in the Amazon Web Services (AWS) S3 cloud storage service. Now Chaos Sumo is making available a free community edition of the Chaos Sumo Smart Object Storage Service intended to enable developers to push data into a data lake running on top of AWS S3 on their own.
Chaos Sumo CTO Thomas Hazel says Chaos Sumo Community Edition provides all the scaffolding required to build a data lake on top of object storage. That capability enables organizations to discover all data sources in AWS S3 buckets; catalogue all of object storage data by type, size, history; determine whether objects are public or private; identify duplicate data for reduced storage costs; and manage objects based on their attributes.
Just as significantly, Hazel says, the scaffolding provided by Chaos Sumo means that organizations can apply analytics to AWS S3 data without ever having to incur the expense of extracting data. Alternatively, Hazel says data can be pushed into a data warehouse such as Redshift or Snowflake that are already run in an AWS cloud.
In general, Hazel says, most organizations today still don’t appreciate all the nuances associated with managing data in the cloud.
“The way you store data in the cloud is much different than it is on-premises,” says Hazel.
The Chaos Sumo provides a layer of abstraction and associated REST application programming interfaces that collectively create a universal file format that provides the foundation for building a data lake on AWS, says Hazel. Obviously, Chaos Sumo is hoping that as more developers invoke the community edition of Chaos Sumo, there will be more of a requirement for the commercial version of the company’s AWS service.
Far too many IT organizations are starting to discover that the pristine data lakes they’ve created in the cloud are turning into swamps where data just winds up being dumped. The issue they face isn’t so much about how to drain that swamp as much as it is to make sure that the data stored in those data lakes is able to easily flow between applications as opposed to simply being left to stagnate.