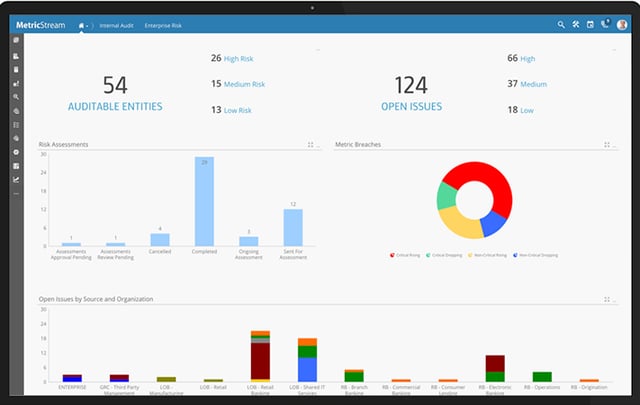
Last year, we spent around $994 million on data quality. That’s a 5 percent increase over 2011, according to The Information Difference, and the total doesn’t include revenue made by consultants and systems integrators who do not work for data quality vendors.
Of that, $825 million went to software sales and maintenance. Data quality makes up 30 percent of the cost for the average master data management project.
But are we spending too much on data quality? Is data quality overrated, as Rajan Chandras posits in a recent Information Week column?
Most people seem to think not. In fact, another Information Difference survey found that 80 percent of its respondents saw a need for more data quality, citing it as of “key importance” to Big Data initiatives.
But Chandras suggests that organizations take a step back and think about what constitutes “good enough” data quality.
While data quality may matter significantly for, say, fraud cases, where you’re verifying identity, there are times when the data may be “good enough” to use, without spending so much time and money on data quality.
Chandras points to MetLife’s NoSQL database project. The insurance company used Mongo, a NoSQL solution that can manage structured, unstructured and semi-structured information without normalizing all the data — a nifty approach that means you don’t need to run an ETL process on the data to use it.
The project allowed MetLife to significantly reduce customer service complexity, reducing 15 different screens to one, and in some cases, 40 required clicks to one. In all, the three-month project involved 70 systems.
But what it did not involve, apparently, was data quality – although MetLife is planning an MDM initiative.
Chandras also shares another example involving Ushahidi, an open source crisis-mapping tool that helps humanitarian groups deliver aid during disasters. Patrick Meier, who is currently the director of Social Innovation at the Qatar Computing Research Institute, and a team of programmers enhanced Ushahidi with algorithms to identify relevant tweets. What they didn’t do was run a data quality test on the data before using it.
The results? Chandras writes:
“But given the quality of incoming data — terse text with an emphasis on emotion rather than nicety of speech — what results can we expect? Not too bad, as it turns out; initial accuracy rates range between 70 and 90 percent. Meier and his team are now working on developing more sophisticated algorithms that can be trained to better interpret incoming messages, leading to continued improvements in accuracy.”
His point is that data can be usable as it is, without a huge data quality initiative behind it.
Okay. Point taken. But it really isn’t shocking, when you consider how long we’ve used data without comprehensive data quality initiatives.
The other thing I took away from that example is that data quality is not just about tools vendors sell. In this rising age of the algorithm, the most important data quality work may happen in the algorithm itself, as the data is pegged and accumulated, rather than after the fact.
Of course, Chandras isn’t arguing against data quality — in fact, he’s very much for it. He’s just saying that sometimes, data quality shouldn’t be a barrier to using the data for some good.
“It’s not a bad idea to take the occasional step back and ask yourself what business value can be obtained from data as is,” he suggests.
But if you do take a step back and realize bad data is an impediment, you might want to check out The Information Difference’s recent report, “The Data Quality Landscape Q1 2013.” It provides an overview of the main data quality vendors, as well as a list of the lesser-known vendors.