

How Hadoop Is Being Used for Business Operations Today
![]()
One of the bigger challenges associated with any Big Data project is mastering the interplay between all the technologies such an initiative entails. Between Hadoop and a host of associated platforms such as the Apache Spark in-memory computing framework and the Kafka messaging system, there’s a lot that can go wrong.
Looking to provide IT organizations with a means of actually monitoring the performance of Big Data environments, Unravel Data this week launched a namesake performance intelligence platform for Big Data applications.
Unravel Data CEO Kunal Agarwal says that Unravel, fresh off raising an additional $7 million in funding, has spent the last few years analyzing over eight million jobs run on Big Data platforms. It has used that information to create a catalog of events that in one way or another lead to performance degradation of a Big Data application. It is now using that repository to compare events in specific Big Data environments to determine the root cause of any given Big Data application issue, says Agarwal.
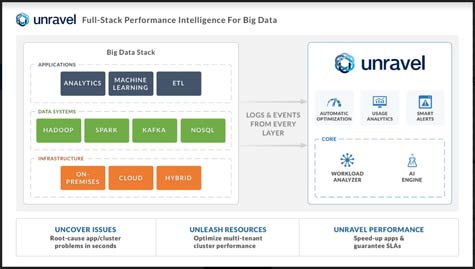
Agarwal says that Unravel, capable of being deployed on premise or in the cloud, relies on sensors that get deployed in the Big Data application. The sensor then provides the instrumentation needed to discover what is occurring within a particular application.
“We can provide an answer as to what is slowing an application or why it simply failed,” says Agarwal.
While monitoring applications has always been a priority for IT organizations, Agarwal says the issue is especially acute when it comes to Big Data. The Big Data scientists usually employed to build these applications typically make hundreds of thousands of dollars. Every minute those Big Data scientists are idle starts to quickly add up.
Naturally, different organizations are going to have varying amounts of success when it comes to Big Data. For all the hype surrounding Big Data, some level of disillusionment is almost a certainty. But from an IT operations perspective, the reason a Big Data project never really gets off the ground should not be because the IT organization couldn’t figure out how to make it run in the first place.
Save
Save