
Five Ways Automation Speeds Up Big Data Deployments
![]()
Looking to extend the reach of its business intelligence across the realm of Big Data, Pentaho today announced data integration capabilities with the Apache Spark in-memory framework for processing Big Data queries.
Donna Prlich, vice president of product marketing for Pentaho, says the initial use cases for Pentaho include being able to orchestrate jobs running on Apache Spark.
Longer term, Prlich says Pentaho is also exploring additional use cases that would enable users of Pentaho software to be able to mingle a variety of types of data processed using Apache Spark alongside a wide variety of other Big Data engines and formats.
The ultimate goal, says Prlich, is to turn Pentaho BI software into a lens through which end users will be able to analyze trends across multiple sources of Big Data without having to master arcane programming tools such as MapReduce.
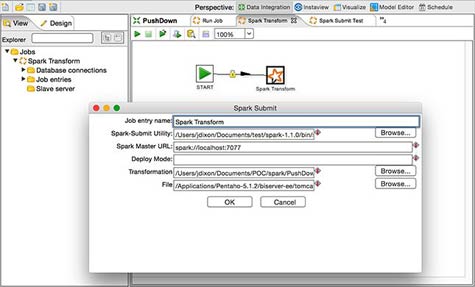
While there is a lot of interest in Apache Spark software, the technology was originally designed to allow a single data scientist to manipulate data in memory. Now Prlich says Apache Spark proponents are hardening that technology to make it robust enough to deploy within multi-user applications running in production.
Because Apace Spark runs in memory, it’s a much faster alternative to MapReduce or a variety of SQL engines that can be deployed on top of Hadoop itself. But like most Big Data technologies, Apache Spark is still something of a work in progress that, in the fullness of time, will augment existing data warehouses by offloading queries against unstructured data from traditional relational and columnar databases that are optimized for processing more structured data.