
There’s an old saying that says you can’t manage what you can’t see. That’s certainly the case when it comes to managing data in the enterprise. But now, that lack of visibility that most IT organizations have into their data is becoming a major issue as companies contemplate the adoption of cloud computing services.
While there are a lot of potential economic benefits to cloud computing, the use of those services will require IT organizations to better segment their data. To help with this process, CA Technologies rolled out this week version 8 of the CA Erwin Data Modeler that features a simplified user interface that makes it easier to visualize the relationships between different sets of data.
According to Donna Burbank, senior director of product marketing for data management at CA Technologies, the core issue is that IT organizations need a simple way to visualize complex data structures in order to figure out where to best run different types of application workloads both inside and outside the enterprise.
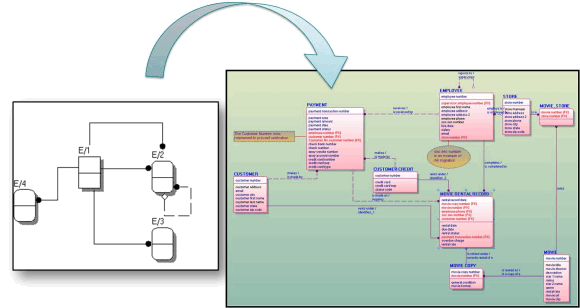
In a world where all applications run on premise, data structures might not be as big an issue because all the applications are running in close proximity to each other. But if an application is moved to a public cloud computing service, the impact on the performance of certain data sets could be profound. In order for IT organizations to embrace cloud computing, they will first need to truly understand the relationships between various sets of data and the potential impact that cloud computing could have on all the applications associated with a particular set of data.
It’s a relatively simple thing to host a stand-alone application in the cloud. But in enterprises where data sets are integrated in innumerable ways, cloud computing presents some difficult data management issues that will need to be carefully navigated. The first step in that process, of course, is actually seeing what it is you’re trying to manage.