
With more than half the data floating around any given enterprise, it’s fairly certain that managing that data more effectively could be a major boon in terms of reducing the number of headaches associated with managing that data and the amount of IT infrastructure needed to support it.
With those twin goals in mind, Hitachi Data Systems (HDS) this week released Hitachi Data Instance Manager software, which not only identifies the most pristine version of a particular set of data, but also allows IT organizations to apply policies against who can actually use it at any given time.
Based on technology that HSD gained with its acquisition last year of Cofio, Hitachi Data Instance Manager is designed to provide a central point of control for a wide range of data management activities, including backup, versioning, replication, archiving, deduplication and continuous data protection (CDP).
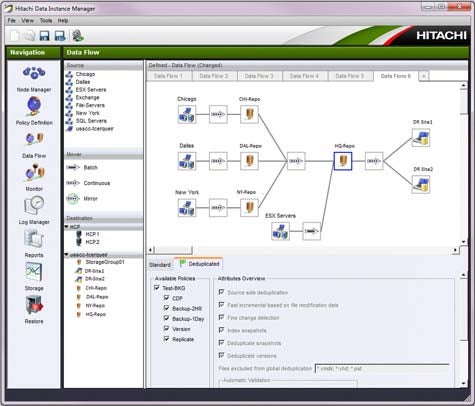
According to Sara Gardner, senior director for HDS software product marketing, the support for replication and snapshots, along with better integration capabilities with Hitachi Content Platform (HCP) for archive, search and recovery, and data analysis will be provided later this year. In fact, Hitachi Data Instance Manager software, when coupled with replication technology in a continuous archiving application, may eliminate the need to do backups all together, says Gardner.
It’s not like organizations deliberately turn a blind eye when it comes to data management. But in the name of enhanced productivity, copies of multiple data sets are made every day. The problem is that no one has a policy engine in place to not only manage who gets access to what data, but also delete copies of data that no one is obviously using anymore.
The savings that can be generated from having an effective framework for managing data in place can be nothing short of profound. If half the data that exists in an enterprise is duplicate, then chances are that half the IT infrastructure deployed to support it is redundant. At a time when IT organizations are under pressure to reduce the total cost of IT more than ever while simultaneously coping with an explosion of data, finding a way to more effectively manage data would logically be the first and best place to start accomplishing those goals.