

Six Warning Signs You’ve Outgrown Your Software
![]()
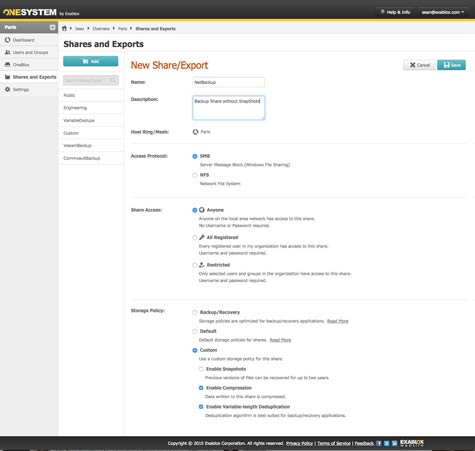
Given the fact that most IT organizations are now storing orders of magnitude more data than they ever did in the past, it should not come as a surprise that usage of data deduplication tools is on the rise. The challenge is that different types of data respond better to different types of data deduplication algorithms.
To make it simpler for IT organizations to invoke those algorithms at the right time, Exablox this week announced that it is adding support for variable-length deduplication to its OneBloxstorage appliances alongside existing support for fixed-length deduplication and inline compression.
Sean Derrington, senior director of product management for Exablox, says that means within the context of a single storage pool, IT organizations can now apply policies to data that automatically invoke the most appropriate approach to data deduplication based on the type of data being stored.
In general, variable-length deduplication is applied to traditional backup and recovery tasks, while fixed-length deduplication lends itself to, for example, video files that might need to be archived in a highly compressed state.
In addition to providing support for the two main classes of data deduplication software, Exablox this week announced that it is giving IT organizations the option of deploying the software it uses to manage OneBlox appliances via the cloud on a private cloud that can be deployed by an internal IT organization.
Derrington says while an Exablox appliance appears to be a network-attached storage (NAS) system to an application, the system itself is based on an object-based architecture that makes it simpler to manage at scale. While most customers are using the management service provided by Exablox in the cloud, Derrington notes that there are scenarios where IT organizations want or need to be able to deploy that management software themselves.
While there’s a lot of debate concerning the pros and cons of object-based storage systems in the enterprise, Derrington says OneBlox appliances are specifically designed to provide access to petabytes of storage that can be scaled-out as needed. The end result is all the management benefits of an object-based storage system without requiring IT organizations to rewrite applications that were designed to interact with traditional NAS systems, says Derrington.
Regardless of the approach most IT organizations adopt going forward, the one thing that is clear is that traditional approaches to storing large amounts of data are at this point severely challenged. Budgets for storage are generally remaining flat, which by definition means IT organizations need to find more efficient ways to store massive amounts of data at a much lower cost per gigabyte. Like it or not, the only way to achieve that goal requires fundamentally rethinking how all that data is stored in the first place.