

Data Lakes: 8 Enterprise Data Management Requirements
![]()
With the rise of microservices architectures and containers, not only are the ways applications are being built transforming, so too are their capabilities. One of the first examples of this transformation comes in the form of a data visualization and analytics application from Zoomdata.
Version 2.2 of the company’s namesake data visualization application, released today, uses microservices and Docker containers to make it simpler for end users to interrogate large amounts of data and more easily connect with external data sources.
Zoomdata CEO Justin Langseth says that approach enabled Zoomdata to design a data visualization tool that natively interacts with Big Data sources such as Apache Spark using a microservices architecture that allows independent services to be combined as needed. Written in Java, Zoomdata takes advantage of Mesos to provide its application with a distributed kernel that enables each application session to dynamically scale up and down in terms of the amount of data being analyzed. That approach, adds Langseth, also provides a multi-tenancy capability and a framework for securing data based on its attributes.
Zoomdata also took advantage of containers to write an application programming interface that makes it simpler to use a software development kit to embed Zoomdata inside another application.
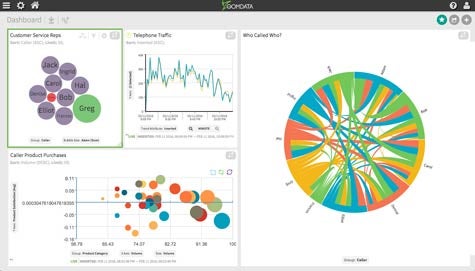
Langseth says Zoomdata expects that many organizations will take advantage of these capabilities to deploy a data visualization application on premise that has all the attributes of a software-as-a-service (SaaS) application without incurring any of the compliance issues associated with cloud applications.
It’ll be a little while longer before more applications employing microservices architectures become more widely available. But as they do, the end-user experience surrounding these applications will be like nothing that has gone before.