
Although there will always be instances where it makes more sense to use MapReduce with Hadoop, it’s pretty clear at this point that most enterprise IT organizations would rather use SQL. MapReduce is not only fairly arcane technology to master, but the vast majority of existing data warehouse applications were designed for SQL.
Recognizing that fact, Cloudera last year began working on Impala, an instance of Hadoop that comes with a processing engine that has been optimized for SQL. The company today announced that the fruits of that effort are now generally available, marking the beginning of what will wind up being the first in a series of processing engines for Hadoop that will include, among others, an engine for Hadoop that is optimized for SAS analytics environments.
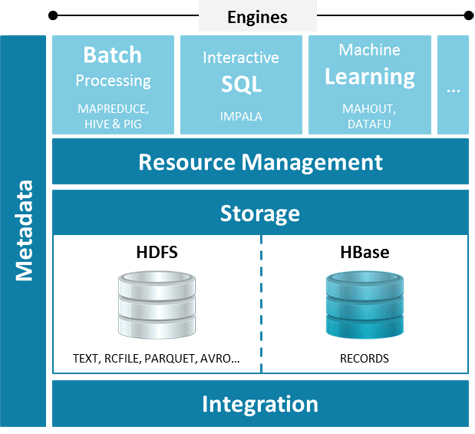
According to Justin Erickson, senior product manager for Cloudera, there will still be certain classes of large-scale, batch-oriented processing jobs that are better handled by MapReduce. But when it comes to iterative queries that require high performance, Cloudera developed an Impala SQL massively parallel database engine that is tightly coupled to Hadoop.
Erickson says, going forward, IT organizations need to realize that multiple type of processing engines can be embedded on top of Hadoop. A SQL engine will be one of the more popular, but it is by no means the only one besides MapReduce that IT organizations should expect to see deployed on top of the Hadoop file system.
Cloudera can pursue this approach, says Erickson, because the company has decoupled the storage system and metadata architecture in a way that allows it to support multiple classes of processing engines on top of Hadoop.
While Hadoop continues to make slow but steady progress in the enterprise, it’s pretty clear that data warehouse applications are going to be federated across both SQL databases and Hadoop. That may not result in a dramatic reduction of the number of SQL databases in the enterprise, but it will most certainly restrict their proliferation. The good news for IT is that not only can they build new classes of Big Data applications by leveraging Hadoop, but the cost of the overall data warehousing environment itself should be a lot more manageable going forward.