
The Challenges of Gaining Useful Insight into Data
![]()
While Hadoop has had the potential to transform the way data warehouses are deployed for quite some time, IT organizations still wind up moving data from Hadoop into a traditional data warehouse, because that’s where the tools for analyzing that data are located. But now, analytics tools that work directly with data stored in Hadoop are becoming available.
Case in point is AtScale, which today launched an OLAP platform called the AtScale Intelligence Platform that enables organizations to use familiar cube models to analyze semi-structured data.
AtScale CEO Dave Mariani says one of the major factors limiting the wholesale shift of data warehouses to Hadoop has been the lack of an OLAP platform that pulls data from Hadoop rather than a traditional SQL database. Once data is moved into the AtScale Intelligence Platform, which Mariani says is the first OLAP platform that works directly against Hadoop data, users can then explore that data using Microsoft Excel or data visualization tools from Tableau Software or QlickView.
With the ability to generate schemas on read using Hadoop, the AtScale Intelligence Platform provides a mechanism through which organizations can finally replace existing data warehouses using a Hadoop platform. It can store all the raw data an organization has at a fraction of the cost that IT organizations have been spending on traditional data warehouses.
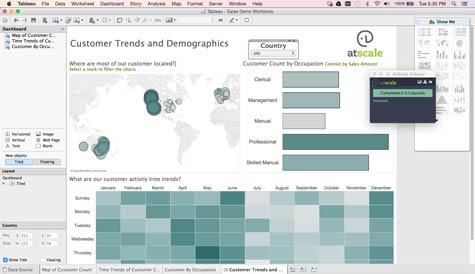
The OLAP capabilities enabled by AtScale, adds Mariani, also eliminate the time and effort that data scientists currently put into finding ways to structure massive amounts of Big Data stored in Hadoop.
Organizations that have already spent millions of dollars building data warehouses are not likely to replace their existing platforms overnight. However, Hadoop is having a profound impact on how data is stored and analyzed across the enterprise. In fact, the challenge that most organizations now face is trying to figure out how many relevant data sources there might be inside and outside of the business.