

5 Steps to Wrangle Uncontrolled Data Flow
![]()
Building a Big Data application is one thing. Trying to live with that application over an extended amount of time is another. Xplenty has been squarely focused on the latter by making available a cloud service that simplifies integration of multiple sources of Big Data. Now Xplenty has acquired Driven, Inc., a provider of application performance management (APM) tools optimized for Big Data applications running on Hadoop that is also the inventor of the open source Cascading project that many organizations employ to manage workflow across Big Data applications.
Fresh off also raising another $4 million in capital, Xplenty CEO Yaniv Mor says that many IT organizations are discovering how challenging Big Data applications are to manage when you consider all the data sources involved.
“There’s always a lot of changes being made to APIs and schemas,” says Mor.
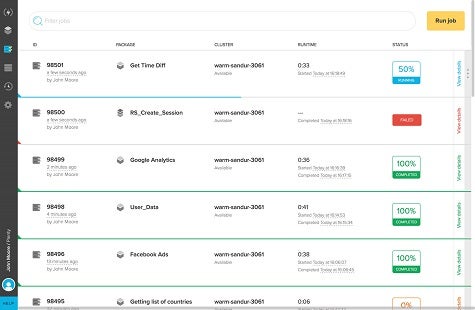
Xplenty, says Mor, is focused on masking all those changes from the IT organization via a service that assumes responsibility for the DevOps processes attached to maintaining a Big Data application. The Driven technologies will be used to extend the scope and reach of that service, says Mor.
Ultimately, Mor says organizations need to decide how much time they want Big Data specialists that make well into six figures spending on Big Data plumbing issues. The goal, says Mor, should be to make it simpler for those specialists to concentrate on analytics that add real value to the business.
Big Data applications running on top of platforms such as Hadoop are poised to come into their own in 2017. But just because an organization built and deployed a Big Data application, it doesn’t necessarily follow that they need to be responsible for every low-level function associated with its ongoing care and maintenance.
Save