

Cognitive Clouds: Gaining a Competitive Advantage
![]()
To make it simpler to pull data into the IBM Watson analytics platform, IBM today announced new connectors for its cognitive computing platform and made it easier to secure data moving between on-premise applications and the IBM Watson cloud service using Docker containers.
In addition to data sources such as IBM DB2, IBM is making available Watson connectors for Amazon Redshift, Apache Hive, Box, Cloudera Impala, Microsoft Azure, Microsoft SQL Server, MySQL, Oracle, Pivotal Greenplum, PostgresSQL, Salesforce.com, Sybase, Sybase IQ and Twitter.
Meanwhile, IBM is also making use of Docker containers to transfer data into the IBM Watson Analytics platform using a secure gateway that borrows technology originally developed for IBM Dataworks, a cloud-based data refinement and access service.
Finally, in conjunction with 10 partners including Twitter, American Marketing Association and The Weather Company, IBM has also created a series of data discovery models, known as Expert Storybooks, which are designed to make it easier for business users to discover relationships between different classes of data stored inside Watson.
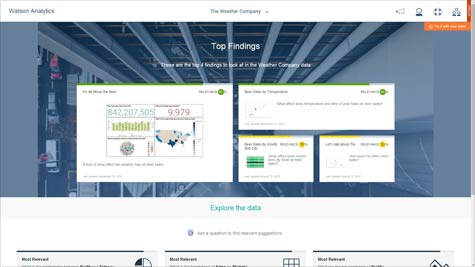
John Colthart, product design leader for IBM Watson Analytics, says that with these latest developments, IBM is trying to democratize access to a service that it has positioned as one of the most advanced forms of cognitive computing that is generally available. IBM now makes it easier to blend and correlate data from multiple data sources, which can then be discovered using Expert Storybooks.
Colthart says IBM already has a half million registered business users accessing IBM Watson. The next challenge facing the company, says Colthart, is getting the next few million users signed up by democratizing access to the IBM Watson Analytics platform as much as possible.