

Capitalizing on Big Data: Analytics with a Purpose
![]()
One of the biggest inhibitors to applying Hadoop in any production environment is the general lack of governance tools for IT organizations to use to manage access permissions for the data that resides there.
To address that issue, Datameer today announced it has embedded a raft of data governance tools inside its analytics software that runs natively on Hadoop.
Matt Schumpert, director of product management at Datameer, says that because its software runs in memory as a Hadoop application, responsibility for data governance within Hadoop naturally falls to Datameer.
To solve that problem, the company is providing access controls within Datameer and publishing open bi-directional REST application programming interfaces (APIs) through which governance metadata can be shared with either open source Apache Sentry authorization software running on Hadoop or any third-party data management software that can consume a REST API.
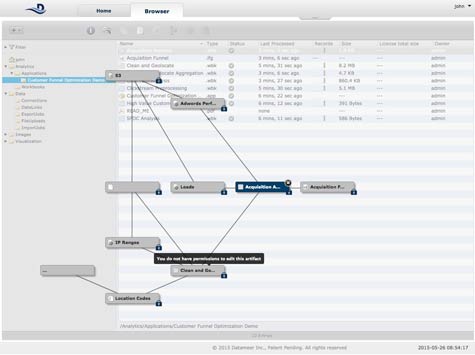
The immediate goal, says Schumpert, is to provide a mechanism for data lineage that shows where analytics results originated and how data and analytics were used, modified or published via the Datameer user interface or the REST API.
Regardless of where the locus for data governance winds up being in the era of Big Data, IT organizations are going to need better governance tools. With more data than ever being collected in platforms such as Hadoop, the amount of sensitive data being actively managed by IT organizations will dramatically increase.
Of course, before any of that can happen, IT organizations still have to identify exactly who is responsible for making sure all those data governance policies are applied regardless of the actual size of the data in question.