
MapR Technologies started out life as one of a few providers of a distribution of Hadoop. Since then, MapR has built an entire distributed computing framework on top of Hadoop. MapR this week extended that framework into the realm of storage.
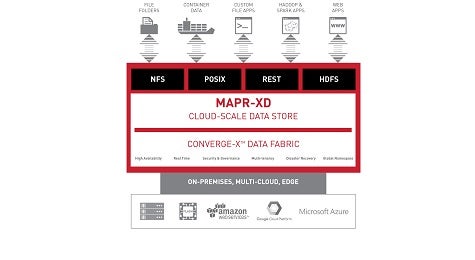
Bill Peterson, senior director for industry solutions for MapR, says MapR-XD will make it simpler for organizations to weave a data fabric as an extension of a distributed MapR Converged Data Platform. That distributed storage software can be layered on top of any storage system to access everything from traditional files to containers being used to drive stateful-applications based on a microservices architecture.
MapR-XD, says Peterson, provides a single global namespace across trillions of files spanning exabytes of data. That capability will enable IT organizations to unify data management across both cloud and on-premises instances of MapR Converged Data Platform, says Peterson. That approach, adds Peterson, also eliminates all the data protection and disaster recovery headaches IT organizations need to manage because data is now universally available across multiple distributed systems.
“There are no silos,” says Peterson. “MapR-XD is designed to be deployed next to the MapR Converged Data Platform.”
Interest in building Big Data lakes that function as the primary source of data for all applications is running high. But providing access to a single data lake often winds up having an adverse impact on I/O performance. Because of that issue, elements of Big Data lakes are being distributed across what might be viewed as ponds of Big Data. The challenge is that any change in one pond needs to be reflected across all the other ponds. Because of that, IT organizations need to rethink their approach to distributed storage before any data lake they create eventually turns into a data swamp that becomes impossible to navigate.