

5 Trends Impacting the Future of Machine Data Intelligence
![]()
The ability to search unstructured data has been around for quite some time. Now, Hewlett-Packard Enterprise (HPE) today announced it has infused the HPE IDOL data analytic engine used to conduct those searches with natural language capabilities.
Jeff Veis, vice president of marketing for Big Data platforms at HPE, says IT organizations can now use IDOL to allow end users to query any data source they care to expose via HPE IDOL, using queries they can type themselves without any intervention on the part of the internal IT organization required.
To achieve that goal, Veis says HPE reengineered IDOL around four cores, IDOL Answer Bank, IDOL Fact Bank, IDOL Passage Extract and IDOL Answer services, and a set of machine-learning algorithms that make it simpler for queries against unstructured data to be organized in a way that optimally responds to natural language queries in a conversational format.
“It’s designed to understand multiple variants of the same query,” says Veis.
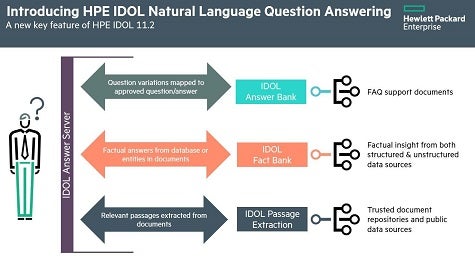
In fact, Veis says the HPE IDOL provides a simpler means for IT organizations to start making cognitive computing applications available to end users in a way that doesn’t require extensive training in a new application developed from the ground up.
HPE IDOL is part of the portfolio of software that will be transferred to Micro Focus, which has been reconstituted into a joint venture in which HPE is the majority owner. The HPE IDOL engine itself was part of the assets that Hewlett-Packard gained when it acquired Autonomy.
The degree to which natural language queries will become the dominant way end users interact with applications remains to be seen. But the more queries that get resolved using this approach, the less time IT professionals will need to spend finding data for end users who are likely to have forgotten the question by the time the IT department finds the answer.
Save