

2016 Data Analytics Forecast: Top 5 Trends to Watch
![]()
Google, in conjunction with Cloudera, Data Artisan, Cask and Talend, announced this week that the Dataflow programming model that Google created to develop streaming Big Data applications is now an open source Apache project.
Talend CTO Laurent Bride says this move is significant because it should give IT organizations more freedom to run their Big Data applications wherever they see fit.
Bride says Dataflow is gaining traction because it provides a programming model that enables developers to build Big Data applications that can run on multiple run-time engines. As a result, code developed using Dataflow can run on MapReduce, Apache Spark and Flink engines.
Longer term, Bride says, Talend is looking at applying its code generation and integration tools to Dataflow in a way that would make it simpler for organizations to marry traditional batch processing applications with modern real-time streaming applications accessing Big Data.
Organizations are starting to appreciate the need for a framework that makes it simpler to both adopt new Big Data processing engines and move between them as needed.
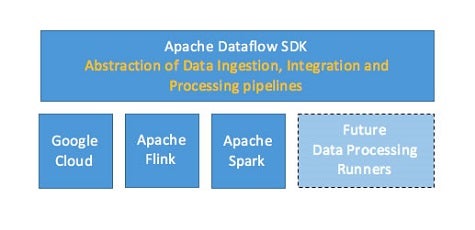
As is often the case with any emerging set of technologies, the pace at which those engines are being developed is all too often faster than the average IT organization can absorb. The Dataflow programming model in effect provides a level of abstraction that enables that level of platform innovation to continue without necessarily having to disrupt all the code development that has gone before.