

Beware the Data Collectors for They Are Us: Privacy and Big Data
![]()
One of the most often underestimated aspects of embracing Big Data is the impact that shifting to a platform such as Hadoop can have on existing queries. The simple fact is that most of the queries organizations run today have been extended multiple times over the years in ways that are usually poorly documented.
Cloudera wants to help IT organizations get a better handle on how their queries are actually structured. Toward this end, it’s including – as part of the version 5.5 update to its distribution of Hadoop – a beta of Cloudera Navigator Optimizer, a tool for analyzing and optimizing queries.
The product is based on technology that Cloudera gained via the acquisition of Xplain.io earlier this year.
Ewa Ding, product manager of Cloudera Navigator Optimizer, says the goal is to enable IT organizations to optimize legacy queries as they move to make Hadoop a core element of their modern data warehouse environments.
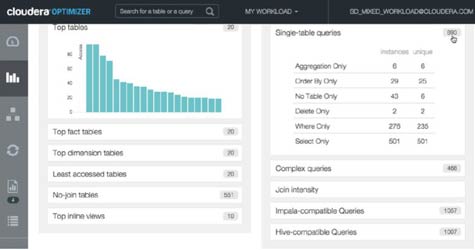
Ding notes that many organizations are somewhat intimidated by the complexity of existing queries. While many organizations rely heavily on the results of those queries to run their business, few people in those organizations actually understand how the queries work. In fact, the person who wrote the original query might have long since moved on from that organization.
What organizations discover is that once they move data into Hadoop, the performance of queries can be adversely affected. That issue has almost nothing to do with Hadoop itself, but rather with the way those queries are structured, says Ding.
Most existing queries need to be optimized to one degree or another even if an organization isn’t embracing Hadoop. The challenge is that, without a tool to actually facilitate that process, manually going through each query to see how it’s actually written winds up being one of those many IT tasks that never gets done.