

Top 10 Storage and Networking Trends for 2014
![]()
When it comes to the IT environment, complexity rules the day. A number of interdependencies between applications running on servers are now being pushed to their maximum utilization rates. The challenge that this creates is that the crash of a single server can have a cascading effect across applications.
To help IT organizations cope, Boundary created an IT monitoring tool designed for running servers at scale. Boundary today is upgrading that namesake tool by providing support for 80 additional server metrics, multi-channel notification capabilities, and integrated collaboration capabilities as well as extended support for additional event sources such as SNMP, Syslog and email.
Boundary CEO Gary Read says that primary differences between Boundary and other tools is both the depth of reporting and the fact that it samples the IT environment every second to provide IT organizations with alerts to any changes.
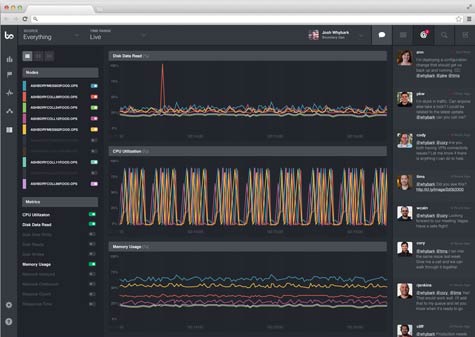
At the speed that servers now routinely operate, Read says IT organization have only about a minute to head off most catastrophic events. Boundary is designed to provide alert information in a way that gives IT the actionable intelligence to identify not only what IT infrastructure elements are suddenly unavailable, but also what applications are being affected. Boundary also now provides an anomaly detection capability that allows customers to be alerted to outliers for any metric by using minimum, maximum, average, or sum ranges across one second to 12-hour intervals.
Enterprise computing has never been more distributed and, as a result, more complicated. The difference between a momentary interruption in service and a truly catastrophic event is often only a couple of minutes. Most end users will never notice a momentary interruption in service. But a catastrophic event tends to bring a lot of attention to the IT department that most organizations would just as soon do without.