

Eight Ways to Put Hadoop to Work in Any IT Department
![]()
Despite the fact that, from a technical perspective, Hadoop is closely aligned with the MapReduce interface for accessing data stored in Hadoop, the primary mechanism for interacting with all that data is still going to be SQL, which for all intents and purposes is the lingua franca of enterprise IT.
In recognition of that reality, Altiscale, a provider of Hadoop as a service in the cloud, this week added support for SQL-on-Hadoop running on the Altiscale Data Cloud.
The new Altiscale offering consists of the Hive 0.13 + Tez SQL query engine running on top of the Hadoop Distributed File System, a Web-based SQL query tool for accessing Hive, and ODBC interfaces that Altiscale has licensed from Simba Technologies.
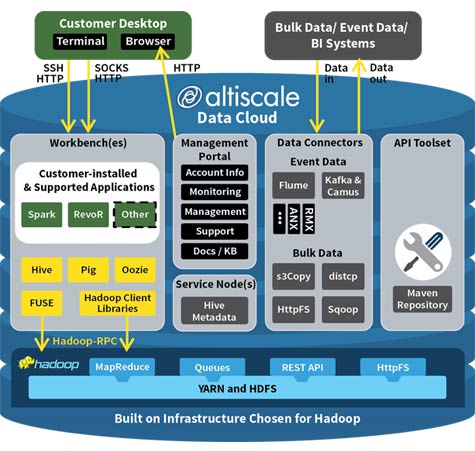
Hive has essentially become a de facto standard for providing SQL access to Hadoop. The Tez engine now allows SQL queries to be executed using YARN (Yet Another Resource Negotiator) on a Hadoop to process SQL requests more efficiently, thereby masking the more arcane MapReduce interface from end users and developers alike.
Steve Kishi, vice president of product management for Altiscale, says that while it’s true that there are probably more instances of Hadoop running on premise than in the cloud today, once enterprise IT organizations begin to run those applications in production, they will increasingly look to take advantage of the economics of storing large amounts of data in the cloud.
The degree to which that will occur, of course, remains to be seen. The one thing that is for certain is that regardless of where Hadoop is running, the way it will be most commonly accessed is SQL.