

Defining Deep Data: What It Is and How to Use It
![]()
For all the excitement that Big Data often generates with an organization, one of the fundamental challenges most of them face comes down to data management plumbing. There’s no shortage of data, but organizing all of it in a way that makes it consumable by a Big Data analytics application is problematic.
To enable IT organizations to manage that process better, Attivio today launched an update to its namesake indexing engine for data within an enterprise that adds a range of self-service capabilities for business analysts and data scientists to identify and unify self-selected data tables from the universal index.
Attivio CEO Stephen Baker says Attivio is squarely focused on applying search and indexing technologies to better manage data assets within an enterprise. All too often, IT organizations have hundreds of enterprise applications, but no one is quite sure what data resides inside each. As a result, these same organizations wind up investing in hiring a data scientist, only to watch the person spend months trying to organize all the data inside the organization. Attivio, says Baker, provides a mechanism to reduce the manual effort associated with integrating all that data by as much as 80 percent.
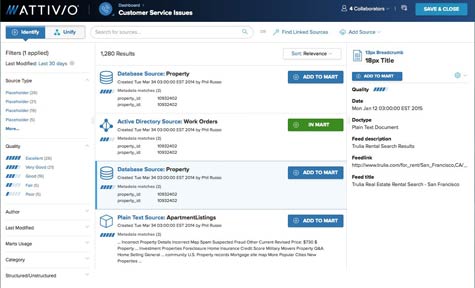
Capable of indexing structured and unstructured data residing in platforms such as Hadoop, Baker says enterprise search technology now needs to evolve well beyond the brute-force implementations of search technologies such as the one Google developed for the Web. While Google can, for example, find all data related to a specific term, Baker says the future of search and indexing engine technologies in the enterprise will be much more tightly integrated with content analytics.
In the meantime, Big Data analytics in general is forcing organizations to confront issues regarding data management that many of them have ignored for decades. The good news is that the ability to automate the profiling and modeling of all that data today could very well provide much needed absolution for the data management sins of the past.