

The Challenges of Gaining Useful Insight into Data
![]()
At the Hadoop Summit 2015 conference today, MapR Technologies advanced its case for the convergence of transaction processing and operational analytics on top of a distribution of Hadoop with an upgrade that automatically synchronizes database, storage and search indices within a real-time application.
Jack Norris, chief marketing officer for MapR, says version 5.0 of the Hadoop distribution from MapR provides support for MapR-DB Table Replication capabilities, which can synchronize data in real time with external compute engines. The first supported external compute engine is Elasticsearch, which means IT organizations will be able to invoke full-text search indexes automatically without having to write custom code.
Other new features in this release include support for the latest version of the YARN resource manager for Hadoop, additional auditing tools, and the DRILL 2.0 SQL Engine that MapR developed. Finally, MapR also unveiled a series of auto-provisioning templates designed to automate the deployment of a Hadoop cluster.
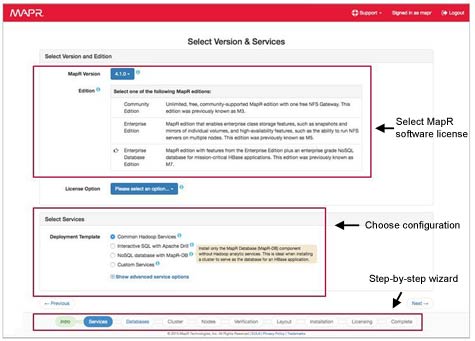
While MapR may not be the market leader when it comes to Hadoop distributions, Norris says that understanding how Hadoop can be used to drive operational analytics in real time will serve to increase its adoption. Rival Hadoop distributions, says Norris, were built assuming that Hadoop would be mainly used in batch processing mode. In reality, Norris contends that Hadoop will be the foundation for building a whole range of new classes of real-time applications.
Given the fact that most IT organizations are still trying to figure out exactly what to do with Hadoop in terms of adding business value, we’re still clearly in the early days of the technology. MapR is betting that when it comes time to turn all those Hadoop data science projects into production applications, more than a few IT organizations are going to discover that the Hadoop distribution upon which they may have first standardized is a lot more limiting than they initially thought. Whether they will be beyond the point of no return by the time they figure that out, however, is still anybody’s guess.