

Top Predictions for Big Data in 2014
![]()
One of the bigger challenges with developing any kind of Big Data application is being able to identify which data is actually relevant. One of the primary tools that developers have been using to accomplish that task is an open source enterprise search and indexing engine developed by Elasticsearch that, as of this week, is now being packaged up into a formal offering.
Elasticsearch CEO Shay Banon says version 1.0 of the company’s namesake search engine adds analytics capabilities that can be federated across multiple data sources, new snapshot and restore capabilities, the ability to aggregate queries across multiple data sources, and an alert function that identifies when any data relevant to a particular query has been added to the system.
Search engines in the context of the enterprise never really took off. But with the rise of Big Data, Banon says it’s clear that developers are going to need a search engine capability that can be easily invoked through an application programming interface (API).
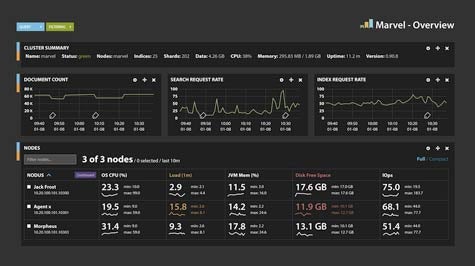
As an open source project, Elasticsearch is already fairly widely used. As a company, Elasticsearch is now making available support and additional functionality that developers of enterprise applications typically require. For example, Elasticsearch just released Elasticsearch Marvel, the company’s first commercial product that helps system operators monitor Elasticsearch deployments in real time, based on ElasticSearch ELK stack, which combines Elasticsearch with Logstash, open source log management software, and Kibana, open source visualization software.
As more organizations look to embrace Hadoop as a foundational component of a larger Big Data strategy, it’s clear that an ability to index and search that data is going to be critical. While there’s no shortage of enterprise search options these days, Elasticsearch has already been downloaded six million times, which suggests the community that is developing around it is becoming large enough to support enterprise-class applications.