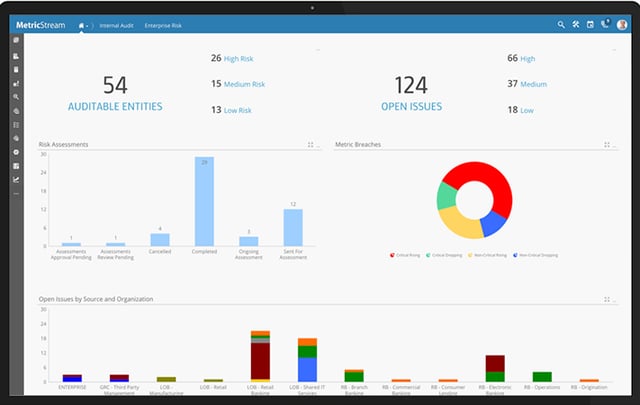
Five Reasons Why You Shouldn’t Move Your Data

Big Data applications are about to jump into the fast lane with the advent of in-memory database technology, a development that is both capitalizing on and fueling the deployment of high-speed infrastructure in the data center.
Oracle recently threw its hat into the in-memory ring with the latest release of Oracle Database. The platform now offers an in-memory option designed primarily to compete with similar functionality from arch-rival SAP. According to CEO Larry Ellison, the switch to in-memory applications from traditional disk or flash storage can boost query and analytics speeds 100-fold, while transaction rates can be doubled. Oracle’s system features a dual-format approach that enables both row and column population for the same data and tables. In this way, processing speeds are increased by cutting logging and change overhead on the CPU. And the system is backed by the new M6-32 database appliance, which doubles the number of cores over current M5 models, raising DRAM memory to 32TB.
The growing momentum behind in-memory solutions hasn’t gone unnoticed in the storage industry. Samsung, for example, has jump-started production on new 20 nm DDR4 modules capable of moving 2.67 Mbps while consuming 30 percent less power than DDR3 solutions. The company already has 4GB devices in the channel and is looking to ramp up deliveries of 16 and 32GB models for top-end server applications by the end of the year.
Whenever you start talking about Big Data, however, scalability becomes a key issue. That’s why system architects are taking a good look at In-Memory Data Grid (IMDG) technology designed to pool the capacity and performance of multiple memory clusters over on-premise or even cloud-based infrastructure. As ScaleOut Software CEO William Bain noted recently, not only can today’s IMDG technology integrate internal and external memory infrastructure, but it can enable real-time analytics across disparate pools of data even in highly dynamic environments. At the same time, it helps to ease cloud migration woes by forming a seamless data repository that does away with the need to re-stage data on a separate cloud-based storage service.
And the notion of cloud-based memory architecture leads to yet another conversation about the need for open standards. A company called Hazelcast is heading in that direction, devising a scheme to commoditize IMDG platforms from Oracle, VMware and others to provide rapid linear scaling for mission-critical applications. The company’s flagship product is designed to enhance Java development through a relatively simple platform that allows grids to scale into the terabit level. In conjunction, the company provides an enterprise edition with enhanced security and elastic memory capabilities, as well as a management system for integrated monitoring and control functions.
Database applications generally sit at the crossroads of enterprise infrastructure. They are usually tasked with processing large amounts of data, so they require access to massive storage banks. At the same time, they need to process data very quickly, so they should be backed with state-of-the-art silicon in both the server and on the network. Today’s in-memory solutions offer all three, and have the added advantage of requiring far lower operating costs than traditional infrastructure, enabling streamlined, even modular, architectures to replace complex, distributed-storage, server and networking infrastructure.
As mobile communications, device-to-device transactions, and a host of other forces push unstructured data volumes into the stratosphere, it looks like the cheapest and most effective way to keep tabs on everything is through greater reliance on simple memory solutions.